{kind=link}
Performance Advances on NVIDIA Blackwell
The NVIDIA Blackwell architecture introduces substantial improvements in both raw computing power and architectural innovations. NVIDIA’s collaboration with OpenAI has focused on leveraging these capabilities transparently through Triton’s compiler infrastructure, particularly in two key areas: matrix multiplications and new precision formats.
Matrix Multiplications
The NVIDIA Blackwell architecture adds a brand-new Tensor Core designed from the ground up for improved throughput and energy efficiency. By extending Triton’s Matrix Multiply-Accumulate (MMA) pipelining machinery, we’ve enabled automatic exploitation of NVIDIA Blackwell’s new Tensor Cores. This required careful analysis of memory access patterns and sophisticated compiler transformations to ensure correct and efficient compute/data-movement overlap.
The result is exceptional performance for both FP8 and FP16 GEMM operations out of the box, with these optimizations automatically applying to any kernel using Triton’s tl.dot primitive. Overall, Triton manages to achieve near-optimal performance, comparable to library implementations across several critical use cases.
Figure 1. Performance improvements with Triton on NVIDIA Blackwell
Flash Attention
Flash attention, a crucial primitive in modern transformer architectures, sees significant speedups on NVIDIA Blackwell through Triton, with up to 1.5x for FP16 attention over the NVIDIA Hopper GPU architecture. While we continue to optimize absolute performance through ongoing compiler enhancements on FP8 and other precisions, the current work helps customers readily transition to NVIDIA Blackwell on Day 0 for existing products. Another important aspect to note here is the ability to deliver this performance gain “for free” with existing Triton flash attention implementations, requiring no code changes.
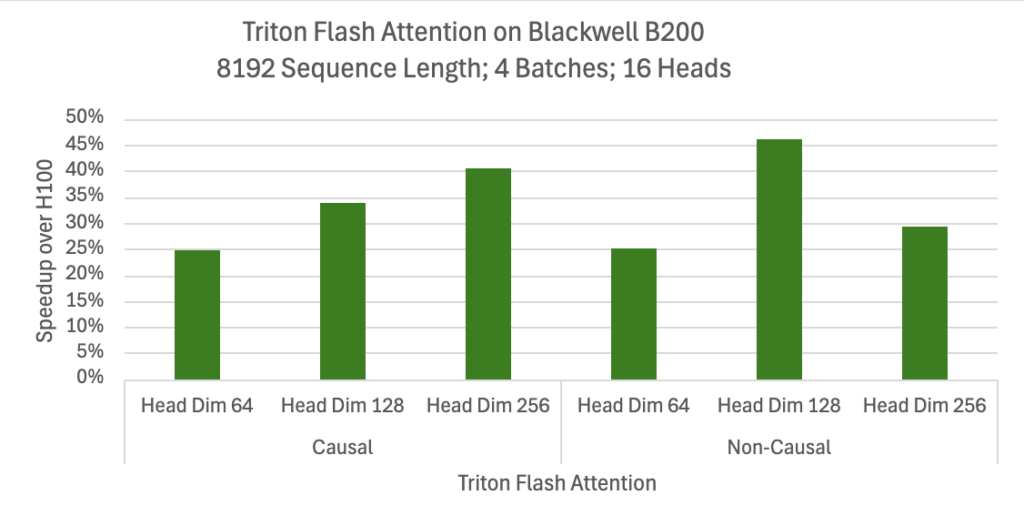
Figure 2. Large performance gains for more complex workloads
New Precision Formats
NVIDIA Blackwell introduces revolutionary block-scaled floating point formats, including the Open Computing Project’s microscaling formats, which Triton now unlocks for NVIDIA Blackwell-powered hardware acceleration. These formats provide higher average precision at higher performance than the non-native block-scaling techniques emulated frequently in LLM inference projects today. For OCP format support, MXFP8 GEMMs on Triton showcase exceptional performance similar to the FP8 GEMMs performance accelerated and shown earlier in this post, while natively allowing for scaling in the Tensor Core. Similarly, MXFP4 provides a new operating point in the precision-performance trade-off space but while offering double the hardware-accelerated performance of FP8 and MXFP8 GEMMs.
To learn more about the new block-scaled floating point support, take a look at the new Triton tutorial dedicated to this functionality.
Areas of Improvement Going Forward
The layout and packing of sub-byte datatype formats like MXFP4 still require care by the end user. We look forward to working with the community to improve the ergonomics for kernel authors and seamless framework integrations.
More Information
Phillippe Tillet, the creator of Triton, and NVIDIA will be diving into the details of this NVIDIA Blackwell work and the resulting performance at the NVIDIA GTC conference on March 17.
Register to attend GTC 2025 virtually or attend live.
This release establishes a powerful foundation for NVIDIA Blackwell support in Triton—but it’s just the beginning. Here’s how you can help shape what’s next:
Start building with Triton on NVIDIA Blackwell today and unlock the full potential of NVIDIA’s latest architecture while maintaining complete control over your development.
Have ideas or encountered issues? Contact our NVIDIA product manager Matthew Nicely by tagging him on GitHub.
FAQs
Q: What are the key benefits of Triton on NVIDIA Blackwell?
A: Triton on NVIDIA Blackwell provides exceptional performance for both FP8 and FP16 GEMM operations, with automatic exploitation of NVIDIA Blackwell’s new Tensor Cores.
Q: How does Triton improve performance for flash attention?
A: Triton’s flash attention performance on NVIDIA Blackwell achieves up to 1.5x speedup for FP16 attention over NVIDIA Hopper GPU architecture.
Q: What are the new precision formats supported by Triton on NVIDIA Blackwell?
A: Triton on NVIDIA Blackwell supports revolutionary block-scaled floating point formats, including Open Computing Project’s microscaling formats, providing higher average precision at higher performance than non-native block-scaling techniques.
Q: How can I get started with Triton on NVIDIA Blackwell?
A: Start building with Triton on NVIDIA Blackwell today and unlock the full potential of NVIDIA’s latest architecture while maintaining complete control over your development.