{kind=link}
Translation plays an essential role in enabling companies to expand across borders, with requirements varying significantly in terms of tone, accuracy, and technical terminology handling. The emergence of sovereign AI has highlighted critical challenges in large language models (LLMs), particularly their struggle to capture nuanced cultural and linguistic contexts beyond English-dominant frameworks. As global communication becomes increasingly complex, organizations must carefully evaluate translation solutions that balance technological efficiency with cultural sensitivity and linguistic precision.
In this post, we explore how LLMs can address the following two distinct English to Traditional Chinese translation use cases:
- Marketing content for websites: Translating technical text with precision while maintaining a natural promotional tone.
- Online training courses: Translating slide text and markdown content used in platforms like Jupyter Notebooks, ensuring accurate technical translation and proper markdown formatting such as headings, sections, and hyperlinks.
These use cases require a specialized approach beyond general translation. While prompt engineering with instruction-tuned LLMs can handle certain contexts, more refined tasks like these often do not meet expectations. This is where fine-tuning Low-Rank Adaptation (LoRA) adapters separately on collected datasets specific to each translation context becomes essential.
Implementing LoRA adapters for domain-specific translation
For this project, we are using Llama 3.1 8B Instruct as the pretrained model and implementing two models fine-tuned with LoRA adapters using NVIDIA NeMo Framework. These adapters were trained on domain-specific datasets—one for marketing website content and one for online training courses. For easy deployment of LLMs with simultaneous use of multiple LoRA adapters on the same pretrained model, we are using NVIDIA NIM.
Refer to the Jupyter Notebook to guide you through executing LoRA fine-tuning with NeMo.
Optimizing LLM deployment with LoRA and NVIDIA NIM
NVIDIA NIM introduces a new level of performance, reliability, agility, and control for deploying professional LLM services. With prebuilt containers and optimized model engines tailored for different GPU types, you can easily deploy LLMs while boosting service performance. In addition to popular pretrained models including the Meta Llama 3 family and Mistral AI Mistral and Mixtral models, you can integrate and fine-tune your own models with NIM, further enhancing its capabilities.
LoRA is a powerful customization technique that enables efficient fine-tuning by adjusting only a subset of the model’s parameters. This significantly reduces required computational resources. LoRA has become popular due to its effectiveness and efficiency. Unlike full-parameter fine-tuning, LoRA adapter weights are smaller and can be stored separately from the pretrained model, providing greater flexibility in deployment.
NVIDIA TensorRT-LLM has established a mechanism that can simultaneously serve multiple LoRA adapters on the same pretrained model. This multi-adapter mechanism is also supported by NIM.
Step-by-step LoRA fine-tuning deployment with NVIDIA LLM NIM
This section describes the three steps involved in LoRA fine-tuning deployment using NVIDIA LLM NIM.
Step 1: Set up the NIM instance and LoRA models
First, launch a computational instance equipped with two NVIDIA L40S GPUs as recommended in the NIM support matrix.
Next, upload the two fine-tuned NeMo files to this environment. Detailed examples of LoRA fine-tuning using NeMo Framework are available in the official documentation and a Jupyter Notebook.
To organize the environment, use the following command to create directories for storing the LoRA adapters:
$ mkdir -p loras/llama-3.1-8b-translate-course
$ mkdir -p loras/llama-3.1-8b-translate-web
$ export LOCAL_PEFT_DIRECTORY=$(pwd)/loras
$ chmod -R 777 $(pwd)/loras
$ tree loras
loras
├── llama-3.1-8b-translate-course
│ └── course.nemo
└── llama-3.1-8b-translate-web
└── web.nemo
2 directories, 2 files
Step 2: Deploy NIM and LoRA models
Now, you can proceed to deploy the NIM container. Replace with your actual NGC API token. Generate an API key if needed. Then run the following commands:
$ export NGC_API_KEY=
$ export LOCAL_PEFT_DIRECTORY=$(pwd)/loras
$ export NIM_PEFT_SOURCE=/home/nvs/loras
$ export CONTAINER_NAME=nim-llama-3.1-8b-instruct
$ export NIM_CACHE_PATH=$(pwd)/nim-cache
$ mkdir -p “$NIM_CACHE_PATH”
$ chmod -R 777 $NIM_CACHE_PATH
$ echo “$NGC_API_KEY” | docker login nvcr.io –username ‘$oauthtoken’ –password-stdin
$ docker run -it –rm –name=$CONTAINER_NAME \
–runtime=nvidia \
–gpus all \
–shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_PEFT_SOURCE \
-v $NIM_CACHE_PATH:/opt/nim/.cache \
-v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \
-p 8000:8000 \
nvcr.io/nim/meta/llama-3.1-8b-instruct:1.1.2
After executing these steps, NIM will load the model. Once complete, you can check the health status and retrieve the model names for both the pretrained model and LoRA models using the following commands:
# NIM health status
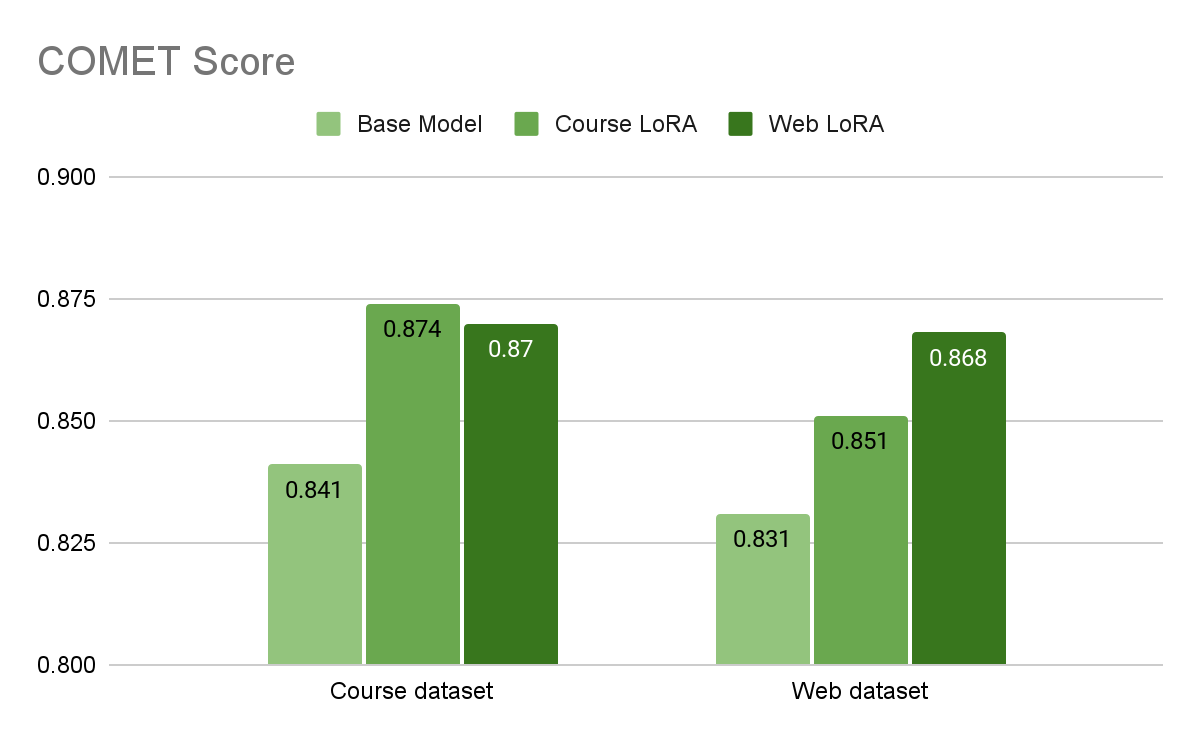
$ curl http://:8000/v1/health/re…uned-645×399.png 645w, https://developer-blogs.nvidia.com/wp-content/uploads/2025/02/bleu-scores-test-datasets-base-model-lora-fine-tuned-485×300.png 485w, https://developer-blogs.nvidia.com/wp-content/uploads/2025/02/bleu-scores-test-datasets-base-model-lora-fine-tuned-146×90.png 146w, https://developer-blogs.nvidia.com/wp-content/uploads/2025/02/bleu-scores-test-datasets-base-model-lora-fine-tuned-362×224.png 362w, https://developer-blogs.nvidia.com/wp-content/uploads/2025/02/bleu-scores-test-datasets-base-model-lora-fine-tuned-178×110.png 178w, https://developer-blogs.nvidia.com/wp-content/uploads/2025/02/bleu-scores-test-datasets-base-model-lora-fine-tuned-1024×633.png 1024w” sizes=”(max-width: 1200px) 100vw, 1200px”/>Figure 1. BLEU scores (higher is better) of different test datasets using the base model and two LoRA fine-tuned models
 Post Views: 98
Post Views: 98