{kind=link}
Write an article about
Enterprise data is constantly changing. This presents significant challenges for maintaining AI system accuracy over time. As organizations increasingly rely on agentic AI systems to optimize business processes, keeping these systems aligned with evolving business needs and new data becomes crucial.
This post dives into how to build an iteration of a data flywheel using NVIDIA NeMo microservices, with a quick overview of the steps for building an end-to-end pipeline.
For a look at how NeMo microservices can be used to address various challenges when building a data flywheel, see Maximize AI Agent Performance Using NVIDIA NeMo Microservices.
Why data flywheels are critical for agentic AI
A data flywheel is a self-reinforcing cycle. Data collected from user interactions improves AI models, which then deliver better results, attracting more users who generate more data, further enhancing the system in a continuous improvement loop. This is similar to the process of capturing experiences and collecting feedback to learn and improve on the job.
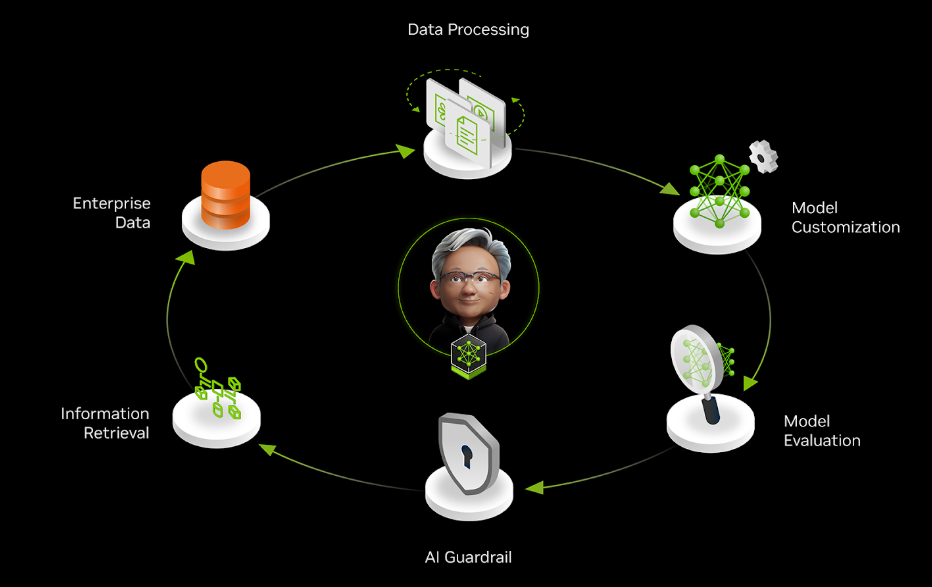 Figure 1. An enterprise AI data flywheel is a continuous cycle
Figure 1. An enterprise AI data flywheel is a continuous cycle
As such, the need for deployed applications to continuously adapt and remain efficient serves as the primary motivation for incorporating a data flywheel into your agentic system.
Need for continuous adaptation
In production environments, AI applications face a persistent challenge: model drift. Consider an AI agent that routes user queries to specialized expert systems. The inputs to this system, the tools it leverages, and their responses all evolve continuously. Without a mechanism to adapt, accuracy inevitably declines due to:
- Updating enterprise knowledge bases and documentation
- Shifting user behavior and query patterns
- Changing tool APIs and responses
For example, a banking large language model (LLM) agent that answers customer questions by querying a transaction SQL (PostgreSQL) database faces significant challenges when the organization adds a new MongoDB dataset with a different schema and updates its response format. Without retraining, the agent continues to formulate queries for the old database structure, leading to failed retrievals or incorrect information. This damages customer trust and potentially creates compliance issues.
Need for efficiency
As these agents grow in complexity to handle more sophisticated tasks, maintaining accuracy and relevancy becomes even more challenging. Additionally, as transaction volumes increase, the computational cost of serving these models rises significantly, making efficiency a critical concern. This is especially problematic for agentic AI systems because they often require multiple inference passes for reasoning, planning, and execution steps—multiplying the computational burden compared to simple single-pass inference models.
When an agent must evaluate several potential actions, query multiple knowledge sources, and validate its outputs, each interaction can require 5x to 10x more compute than a standard model inference, dramatically increasing infrastructure costs as usage scales.
Using customization techniques, you can optimize the smaller models to match the accuracy of much larger models, thus reducing latency and total cost of ownership (TCO). Additionally, as newer and more capable models emerge, continuously evaluating these models (alongside their fine-tuned variants), leveraging user interaction data can ensure sustained performance and adaptability.
Using NVIDIA NeMo microservices to power your data flywheel
NVIDIA NeMo microservices provide an end-to-end platform for building data flywheels, enabling enterprises to continuously optimize their AI agents with the latest information.
As shown in Figure 2, NVIDIA NeMo helps enterprise AI developers easily curate data at scale, customize LLMs with popular fine-tuning techniques, consistently evaluate models on industry and custom benchmarks, and guardrail them for appropriate and grounded outputs.
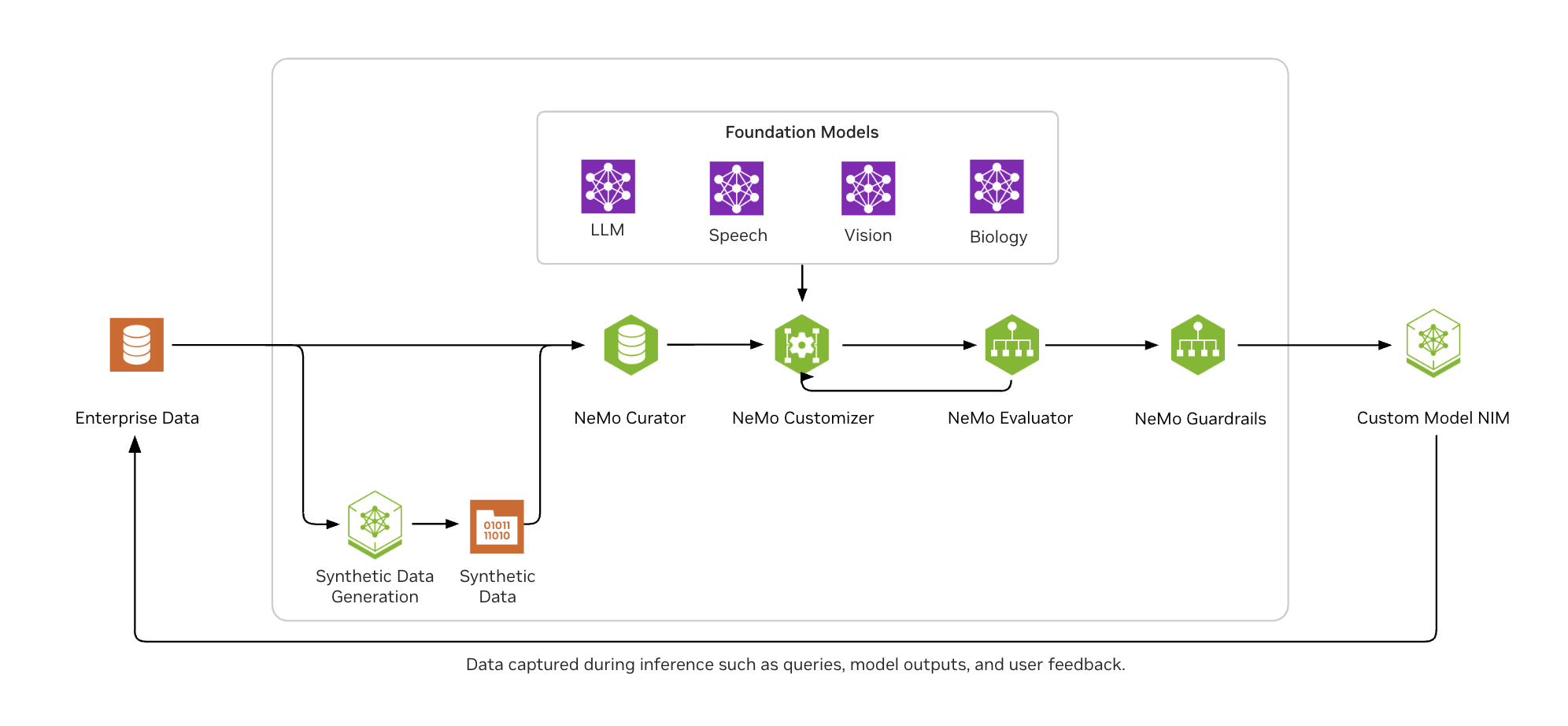 Figure 2. NVIDIA NeMo microservices provide an end-to-end model customization and deployment workflow
Figure 2. NVIDIA NeMo microservices provide an end-to-end model customization and deployment workflow
To illustrate an end-to-end pipeline with NeMo microservices, take the example of tool calling in agents. Tool calling enables LLMs to interact with external systems, execute programs, and access real-time information unavailable in their training data.
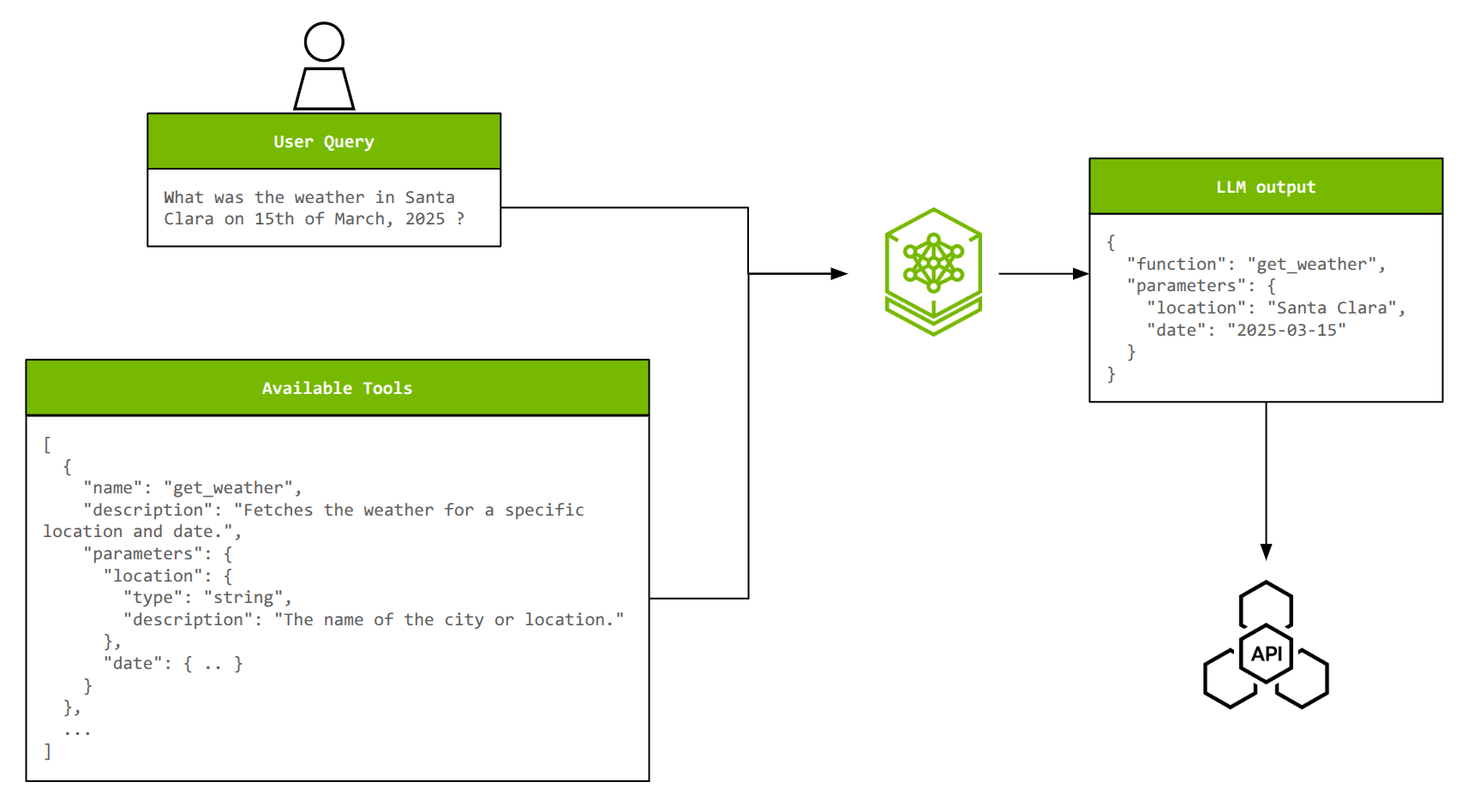 Figure 3. Example of a single-turn tool call
Figure 3. Example of a single-turn tool call
For effective tool calling, an LLM must select the correct tool from available options, extract appropriate parameters from natural language queries, and potentially chain multiple actions together or call multiple tools in parallel. As the number of tools and their complexity increases, customization becomes critical for maintaining accuracy and efficiency.
By fine-tuning a Llama 3.2 1B Instruct model on the xLAM dataset (~60,000 tool calling examples), it is possible to achieve tool calling accuracy close to a Llama 3.1 70B Instruct model, thereby reducing the model size by 70x.
The following sections outline the key steps to give you a quick overview. Check out the full tutorial in the Jupyter notebooks.
Step 1: Deploy NVIDIA NeMo microservices
The NeMo microservices platform is available in the form of Helm charts that can be deployed on a Kubernetes-enabled system of your choice. To get started, you can use minikube on a single-node NVIDIA GPU cluster with at least two NVIDIA GPUs (NVIDIA A100 80 GB or NVIDIA H100 80 GB).
Step 2: Data preparation
The xLAM dataset is transformed into formats compatible with NeMo Customizer for training and NeMo Evaluator for testing. Each data sample is a json object – composed of a user query, a list of available tools (along with their descriptions and parameters), and the ground truth response (a selected tool with parameters). In addition, data splits are created for training, validation, and testing.
The data format for NeMo Customizer is shown below. Note that messages includes the user query and assistant’s ground truth response, and tools includes a list of available tools to choose from.
{
“messages”: [
{
“role”: “user”,
“content”: “Where can I find live giveaways for beta access?”
},
{
“role”: “assistant”,
“tool_calls”: [
{
“id”: “call_beta”,
“type”: “function”,
“function”: {
“name”: “live_giveaways_by_type”,
“arguments”: {“type”: “beta”}
}
},
]
}
],
“tools”: [
{
“type”: “function”,
“function”: {
“name”: “live_giveaways_by_type”,
“description”: “Retrieve live giveaways from the GamerPower API based on the specified type.”,
“parameters”: {
“type”: “object”,
“properties”: {
“type”: {
“type”: “string”,
“description”: “The type of giveaways to retrieve (e.g., game, loot, beta).”,
“default”: “game”
}
},
“required”: []
}
}
}
]
}
NeMo Evaluator follows this format very closely, with a minor difference. More information can be found in the Jupyter notebook.
Step 3: Entity management
The NVIDIA NeMo Entity Store microservice manages organizational entities such as namespaces, projects, datasets, and models, offering a hierarchical structure for efficient resource management. By doing this, it enables seamless collaboration and prevents resource conflicts across multiple users. The NVIDIA NeMo Datastore microservice, on the other hand, handles the actual files associated with these entities, supporting operations like uploading, downloading, and versioning.
In this step, the prepared datasets are uploaded to the NeMo Datastore through its supported integration with the Hugging Face Hub interface (HfApi), and registered to both Entity Store and Datastore through REST API calls. NeMo Customizer and Evaluator reference these paths for their inputs.
Step 4: Low-rank adaptation (LoRA) fine-tuning
NeMo Customizer is leveraged for LoRA finetuning of the Llama 3.2 1B Instruct model. Triggering a customization job and monitoring job status are also REST API calls to the NeMo Customizer endpoint. Training parameters can be configured just like any other deep learning training job. In addition, NeMo Customizer seamlessly integrates with Weights & Biases for monitoring training runs.
headers = {“wandb-api-key”: WANDB_API_KEY} if WANDB_API_KEY else None
training_params = {
“name”: “llama-3.2-1b-xlam-ft”,
“output_model”: f”{NAMESPACE}/llama-3.1-8b-xlam-run1″,
“config”: BASE_MODEL,
“dataset”: {“name”: DATASET_NAME, “namespace” : NAMESPACE},
“hyperparameters”: {
“training_type”: “sft”,
“finetuning_type”: “lora”,
“epochs”: 2,
“batch_size”: 16,
“learning_rate”: 0.0001,
“lora”: {
“adapter_dim”: 32,
“adapter_dropout”: 0.1
}
}
}
# Trigger the job.
resp = requests.post(f”{NEMO_URL}/v1/customization/jobs”, json=training_params, headers=headers)
customization = resp.json()
# Used to track status
JOB_ID = customization[“id”]
# This will be the name of the model that will be used to send inference queries to
CUSTOMIZED_MODEL = customization[“output_model”]
Step 5: Inference
Once the model is trained, its LoRA adapter is saved in the NeMo Entity Store and is picked up automatically by NVIDIA NIM. You can test the model by sending a prompt to its NIM endpoint.
inference_client = OpenAI(
base_url = f”{NIM_URL}/v1″,
api_key = “None”
)
completion = inference_client.chat.completions.create(
model = CUSTOMIZED_MODEL,
messages = test_sample[“messages”],
tools = test_sample[“tools”],
tool_choice = ‘auto’,
temperature = 0.1,
top_p = 0.7,
max_tokens = 512,
stream = False
)
print(completion.choices[0].message.tool_calls)
This should produce an output that includes the name of the tool along with populating its parameters:
[ChatCompletionMessageToolCall(id=’chatcmpl-tool-bd3e4ee65e0641b7ae2285a9f82c7aae’,
function=Function(arguments='{“type”: “beta”}’, name=’live_giveaways_by_type’), type=’function’)]
At this point, the model is ready for evaluation to quantify its accuracy on tool calling.
Step 6: Evaluation
The fine-tuned model is evaluated using NeMo Evaluator, comparing its accuracy against the base model. Metrics like function_name_accuracy and function_name_and_args_accuracy highlight improvements in tool-calling capability. These metrics, as their names imply, calculate string matching accuracy for function names and their arguments.
Evaluation generally consists of the following parts:
1. Creating an evaluation configuration: This tells NeMo Evaluator details about your desired evaluation such as the dataset to use, number of test samples, metrics, and more.
simple_tool_calling_eval_config = {
“type”: “custom”,
“tasks”: {
“custom-tool-calling”: {
“type”: “chat-completion”,
“dataset”: {
“files_url”: f”hf://datasets/{NAMESPACE}/{DATASET_NAME}/testing/xlam-test.jsonl”,
“limit”: 50
},
“params”: {
“template”: {
“messages”: “{{ item.messages | tojson}}”,
“tools”: “{{ item.tools | tojson }}”,
“tool_choice”: “auto”
}
},
“metrics”: {
“tool-calling-accuracy”: {
“type”: “tool-calling”,
“params”: {“tool_calls_ground_truth”: “{{ item.tool_calls | tojson }}”}
}
}
}
}
}
2. Triggering the evaluation job: This includes specifying the evaluation configuration, along with the custom model (NIM) that it should evaluate.
res = requests.post(
f”{NEMO_URL}/v1/evaluation/jobs”,
json={
“config”: simple_tool_calling_eval_config,
“target”: {“type”: “model”, “model”: CUSTOM_MODEL_NAME}
}
)
base_eval_job_id = res.json()[“id”]
3. Review the evaluation metrics: Once the evaluation job is complete, reviewing metrics is also a REST call.
res = requests.get(f”{NEMO_URL}/v1/evaluation/jobs/{base_eval_job_id}/results”)
ft_function_name_accuracy_score = res.json()[“tasks”][“custom-tool-calling”][“metrics”][“tool-calling-accuracy”][“scores”][“function_name_accuracy”][“value”]
ft_function_name_and_args_accuracy = res.json()[“tasks”][“custom-tool-calling”][“metrics”][“tool-calling-accuracy”][“scores”][“function_name_and_args_accuracy”][“value”]
If you follow the provided demonstrative notebook, you should see a significant bump, as compared to the base meta/llama-3.2-1B-instruct model. You can expect, roughly:
- function_name_accuracy: 12% to 92%
- function_name_and_args_accuracy: 8% to 72%
This comes very close to the accuracy of the base meta/llama-3.1-70B-instruct on this task, a model 70x its size.
Step 7: Guardrailing
The last part of this pipeline is to add guardrails to your custom model NIM. In this case, we enforce content safety using nvidia/llama-3_1-nemoguard-8b-content-safety, which moderates human-LLM interaction content and classifies user prompts and LLM responses as safe or unsafe. If the content is unsafe, the model additionally returns a response with a list of categories that the content violates.
Similar to evaluation, this consists of the following:
1. Creating and registering a guardrails configuration: Note that the model is informed of unsafe categories to detect, along with the format it should provide its response in.
data = {
“name”: “toolcalling”,
“namespace”: “default”,
“data”: {
“models”: [
{
“type”: “content_safety”,
“engine”: “nim”,
“model”: “nvidia/llama-3.1-nemoguard-8b-content-safety”
}
],
“rails”: {
“input”: {
“flows”: [
“content safety check input $model=content_safety”
]
},
“dialog”: {
“single_call”: {
“enabled”: False
}
}
},
“prompts”: [
{
“task”: “content_safety_check_input $model=content_safety”,
“messages”: [
{
“type”: “system”,
“content”: “Task: Check if there is unsafe content in the user or agent messages in the below conversation in accordance with our
safety policy with the below categories. Provide a ‘safe’ or ‘unsafe’ rating for both the user message and the agent response. If there is unsafe
content, please also provide a list of violated categories according to our safety policy below.\n\n\nS1: Violence.\nS2: Sexual.\nS3: Criminal Planning/Confessions.\nS4: Guns and Illegal Weapons.\nS5: Controlled/Regulated
Substances.\nS6: Suicide and Self Harm.\nS7: Sexual (minor).\nS8: Hate/Identity Hate.\nS9: PII/Privacy.\nS10: Harassment.\nS11: Threat.\nS12:
Profanity.\nS13: Needs Caution.\nS14: Other.\nS15: Manipulation.\nS16: Fraud/Deception.\nS17: Malware.\nS18: High Risk Gov Decision
Making.\nS19: Political/Misinformation/Conspiracy.\nS20: Copyright/Trademark/Plagiarism.\nS21: Unauthorized Advice.\nS22: Illegal
Activity.\nS23: Immoral/Unethical.\nS24: Deleting Logs.\n\n\n\nuser:
{{user_query}}\n\n\nProvide your safety assessment for the above conversation in the below output JSON
format:\n{\”User Safety\”: safe or unsafe rating for the user message, \”Response Safety\”: safe or unsafe rating for the agent response.
Omit if no agent response present. \”Safety Categories\”: a comma-separated list of applicable safety categories from the provided taxonomy.
Omit if all safe.}\n\nDo not include anything other than the output JSON in your response.\nOutput JSON:”
},
{
“type”: “user”,
“content”: “{{ user_input }}”
}
],
“output_parser”: “nemoguard_parse_prompt_safety”,
“max_tokens”: 50
}
]
},
}
# Register the guardrails configuration
response = requests.post(GUARDRAILS_URL, json=data)
2. Adding guardrails to user input before the LLM NIM inference call
payload = {
“model”: BASE_MODEL,
“messages”: [
{
“role”: “user”,
“content”: user_message
}
],
“guardrails”: {
“config_id”: “toolcalling”
},
“temperature”: 0.2,
“top_p”: 1
}
# Check for unsafe user message in guardrails
response = requests.post(f”{NEMO_URL}/v1/guardrail/checks”, json=payload)
status = response.json()
if status == “success”:
# SAFE
… (Proceed with your LLM inference call as in step 5)
else:
# UNSAFE
print(f”Not a safe input, the guardrails have resulted in status as {status}. Tool-calling shall not happen”)
Get started
By following the steps outlined in this post, you can construct an end-to-end pipeline for model customization, inference, evaluation, and guardrailing using NeMo microservices. When this pipeline is automated to process a continuous stream of data—triggered periodically or upon detecting drift—you establish a data flywheel. This self-reinforcing loop enables your system to continuously learn, adapt, and improve, driving sustained performance enhancements over time.
NVIDIA NeMo microservices are now generally available for download. Download the microservice and use the tutorial notebook and associated video to get started with the example showcased in this post.
To learn more about NeMo microservices, refer to the documentation. To run NeMo microservices in production, request a 90-day free license for NVIDIA AI Enterprise.
.Organize the content with appropriate headings and subheadings ( h2, h3, h4, h5, h6). Include conclusion section and FAQs section with Proper questions and answers at the end. do not include the title. it must return only article i dont want any extra information or introductory text with article e.g: ” Here is rewritten article:” or “Here is the rewritten content:”