{kind=link}
Write an article about
Many libraries and tools perform various tasks in processing files, images, and documents. PDF files are a good example of files that can undergo several processing stages using Python libraries and AI models.
Reducing the size of a PDF file can be necessary for various reasons, and various tools can accomplish this. One fascinating way is to use the PyMuPDF library. This library is designed for various tasks, including extracting text, creating images from documents, adding images to documents, and performing optical character recognition (OCR) on document pages.
However, it can also employ a special technique to reduce the file size of a PDF. This article will examine how Hanif utilized the PyMuPDF library to accomplish this task.
What is PyMuPDF?
PyMuPDF is a Python library that excels in extracting, analyzing, manipulating, and converting data from PDF files and other document formats. With this library, you can extract text and images from a PDF file. But its capabilities do not end here. PyMuPDF can also extract vector graphics and merge PDF files.
Another interesting feature of this library is its ability to manipulate and process PDF files. This library can perform a range of tasks, including adding watermarks and images, as well as embedding and attaching files.
How Do PDFs Get Bloated?
There are several reasons why a PDF file can become too large. High image resolutions, embedded fonts, unused objects, and other factors can affect the size of these files. Compressing them is a very effective optimization technique, as it can provide a better overall experience. Compressing larger PDF files is important for several reasons, including saving storage space, improving web performance, and facilitating easy sharing.
Reducing PDF files using PyMuPDF involves a seamless method. This library can operate in low-resource environments and yield excellent results. We’ll explore how this technique creates the tool and how you can achieve your desired results.
How to Reduce PDF Using this Library
We can begin by setting up the environment and utilizing PyMuPDF to compress the size of a PDF file. Then, we can install the essential modules for processing the file. So, let’s dive in.
Setting up the environment
To run this operation, you must install the PyMuPDF Python library, which allows you to work with PDF files and other document formats.
!pip install pymupdf
Importing the Necessary Libraries
import os
import fitz # PyMuPDF
This operation requires two libraries: OS and Fitz. The OS library provides functions that enable interaction with the operating system by managing file paths. The PyMuPDF library’s main module is Fitz, responsible for handling PDFs and other document formats. Fitz can easily open, load, read, and manipulate PDF files, which is particularly significant for tasks involving size reduction.
Compressing the PDF file
def compress_pdf(input_path, output_path, zoom_x=0.75, zoom_y=0.75):
try:
document = fitz.open("input_path")
new_document = fitz.open()
This function is designed to compress PDF files by reducing the size of their pages. The function loads the original PDF file using the PyMuPDF library, also known as fitz.open function. Then, it creates a new empty document that allows you to add the compressed file.
PDF operation.
In addition to setting the function that opens the original file and creates a new document, you must set the structure for compressing the file in a suitable format.
for page_num in range(len(document)):
page = document.load_page(page_num)
mat = fitz.Matrix(zoom_x, zoom_y)
pix = page.get_pixmap(matrix=mat, alpha=False)
img_bytes = pix.tobytes("jpeg")
new_page = new_document.new_page(width=pix.width, height=pix.height)
new_page.insert_image(new_page.rect, stream=img_bytes)
This block loops through each page of the original PDF. For every page, it creates a scaling matrix (fitz.Matrix) to reduce the page content, renders the page as a pixmap (image), converts it to JPEG bytes, and then inserts the image into a new, blank page in the new, compressed PDF. This process effectively reduces the file size by saving the visual content as images.
Saving Newly Compressed PDF
new_document.save(output_path)
new_document.close()
document.close()
This code helps you save the newly compressed PDF file to the output_path. However, it closes the original and compressed documents to free up memory. This ensures all changes are written and no files are left open in memory.
Results
print(f"✅ Compressed: {output_path}")
print(f" Original: {os.path.getsize(input_path)/1024:.2f} KB")
print(f" Compressed: {os.path.getsize(output_path)/1024:.2f} KB")
With this code, you can display the path to the compressed file and also view the sizes of the original and the new documents. This operation is carried out using the os.path module. getsize() to get the size of the new document. The output is also formatted to two decimal points, which helps with readability.
Batch PDF Compression and Error Handling
except Exception as e:
print(f"❌ Error compressing {input_path}: {str(e)}")
if __name__ == "__main__":
folder = "/content"
if not os.path.isdir(folder):
raise FileNotFoundError(f"Folder '{folder}' does not exist.")
pdf_files = [f for f in os.listdir(folder) if f.endswith(".pdf")]
if not pdf_files:
print("⚠️ No PDF files found in the folder.")
else:
for filename in pdf_files:
input_pdf = os.path.join(folder, filename)
output_pdf = os.path.join(folder, filename.replace(".pdf", "-compressed.pdf"))
compress_pdf(input_pdf, output_pdf)
This code handles errors during compression with a try-except block. If something goes wrong, it catches the exception and prints an error message showing which file failed and why. Then, in the main execution block, it sets a folder path (in this case, /content) where the PDF files are located.
It checks if the folder exists and raises an error if it doesn’t. Next, it looks for all PDF files in that folder. If no PDFs are found in the folder, a warning is printed. Otherwise, it loops through each PDF file, creates a new output filename for the compressed version, and calls the compress_pdf() function to perform the compression.
Results
Running this code locally yields the output of your compressed document, tagged as ‘compressed.’ All these operations are in the folder; you can get a resized PDF.
Application of PyMuPDF for Reducing File Size
This tool is particularly useful in various settings where file size reduction is crucial. Good examples include Email Attachment optimization, improved web and app performance, and archiving and storage management.
In many corporate workplaces, email attachments are limited (e.g., 20MB), but with PyMuPDF, you can compress files, reports, proposals, and other documents to stay within the given limits.
A reduced size can also enhance loading speed and improve the user experience. This is especially necessary for institutions, banks, academic institutions, and legal organizations that host online PDF files.
Optimizing storage is another reason why the tool is relevant. Hospitals, firms, government agencies, and even some businesses store a large archive of PDF documents. Reducing file size is essential for saving storage and memory.
Exploring PyMuPDF With Streamlit
You can apply this compressor using a simple user interface with Streamlit to power the compression algorithm. This tool can help you set up a page that can handle these files. Therefore, you can test the compressor while also allowing usage for individuals with a deep technical understanding of coding.
This section will explain a simple guide to setting up a page to run this compression tool.
Page Setup
The first step in using Streamlit is to utilize its page setup features. This allows you to create a centered heading and minimalist interface where you can add attributes, links, buttons, file uploads, and other inputs. In this case, using PyMuPDF would require adding an interface to upload files, which brings us to the next step.
File Handling
You can use the bordered container on Streamlit to create a file uploader that accepts only PDF files. This attribute helps you handle the uploaded file effectively, as it allows you to avoid saving the file on disk.
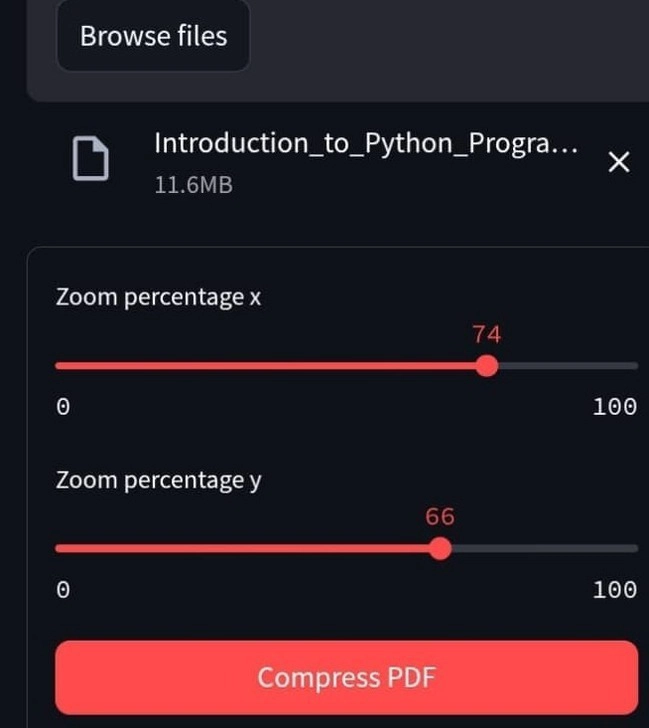
User Control (Added Feature)
This tool features a high-quality slider that ranges from 0 to 100, allowing users to control the desired compression level precisely.
Displays an informative message explaining that a lower quality setting results in a smaller file size. Features a large “Compress PDF” button that spans the width of the container, making it highly visible and easy to click.
Processing Flow
When a PDF is uploaded, the app captures the file name and size, then enables compression options. Upon clicking “Compress PDF,” a loading spinner appears, the file is processed using temporary storage, and the compression algorithm is executed.
After compression, it displays file size comparisons, provides a download button, and shows an error message if compression fails.
Running Streamlit Locally
As we mentioned earlier, this platform allows you to set up a simple User Interface to host your mini projects. It also permits simple attributes, such as buttons, file uploaders, and links. Here is a simple guide on how to run this;
Clone the GitHub repo
Navigate to and clone the GitHub Repository at https://github.com/Hanif-adedotun/compress-pdf.git
- Navigate to the root of the folder
- Open up the terminal on the path
- Run pip install -r requirements.txt
- Run streamlit streamlit.py
- Open up your browser at localhost:8501
Voila! You now have access to the localhost version of the project running on your system.
Install Streamlit
Pip install Streamlit
Once you have successfully installed it, you can run the Python code. If you encounter no errors, it means Streamlit has been installed successfully.
Run the Streamlit File
Streamlit run filename.py
This command will direct you to a local URL on your web browser, and you can then proceed to start building your page.
With this tool, you can use Streamlit’s basic functions and attributes to run your mini projects, like the PDF compressor. There are lots of features you can add with little to no knowledge of HTML and CSS. Check out this guide for more information on using Streamlit.
Wrapping Up
The article examines how the PyMuPDF Python library effectively compresses the size of PDF files. Users can optimize PDFs for email, web, and storage by converting pages to compressed images and rebuilding the document.
Hanif demonstrates a practical and effective method using simple code, batch processing, and error handling. This technique is particularly valuable for organizations that handle large volumes of digital documents.
.Organize the content with appropriate headings and subheadings ( h2, h3, h4, h5, h6). Include conclusion section and FAQs section with Proper questions and answers at the end. do not include the title. it must return only article i dont want any extra information or introductory text with article e.g: ” Here is rewritten article:” or “Here is the rewritten content:”