{kind=link}
NVIDIA Announces World-Record DeepSeek-R1 Inference Performance
NVIDIA announced world-record DeepSeek-R1 inference performance at NVIDIA GTC 2025. A single NVIDIA DGX system with eight NVIDIA Blackwell GPUs can achieve over 250 tokens per second per user or a maximum throughput of over 30,000 tokens per second on the massive, state-of-the-art 671 billion parameter DeepSeek-R1 model. These rapid advancements in performance at both ends of the performance spectrum were made possible by improvements to the NVIDIA open ecosystem of inference developer tools, now optimized for the NVIDIA Blackwell architecture.
These performance records will improve as the NVIDIA platform continues to push the limits of inference on the latest NVIDIA Blackwell Ultra GPUs and NVIDIA Blackwell GPUs.
Figure 1: NVIDIA B200 GPUs in an NVL8 configuration, running TensorRT-LLM software, deliver the highest published tokens per second per user on the full DeepSeek-R1 671B model
Crafting High-Performance Blackwell Kernels with CUTLASS
CUTLASS, since its 2017 debut, has been instrumental for researchers and developers implementing high-performance CUDA kernels on NVIDIA GPUs. By providing developers with comprehensive tools to design custom operations, such as GEMMs and Convolutions, targeting NVIDIA Tensor Cores, it has been critical for the development of hardware-aware algorithms, powering breakthroughs like FlashAttention and establishing itself as a cornerstone for GPU-accelerated computing.
With the release of CUTLASS 3.8, we’re extending support to NVIDIA Blackwell architecture, enabling developers to harness next-generation Tensor Cores with support for all new data types. This includes the new narrow precision MX formats and NVIDIA’s own FP4, empowering developers to optimize custom algorithms and production workloads with the latest innovations in accelerated computing. Figure 7 shows that we are able to achieve up to 98% relative peak performance for Tensor Core operations.
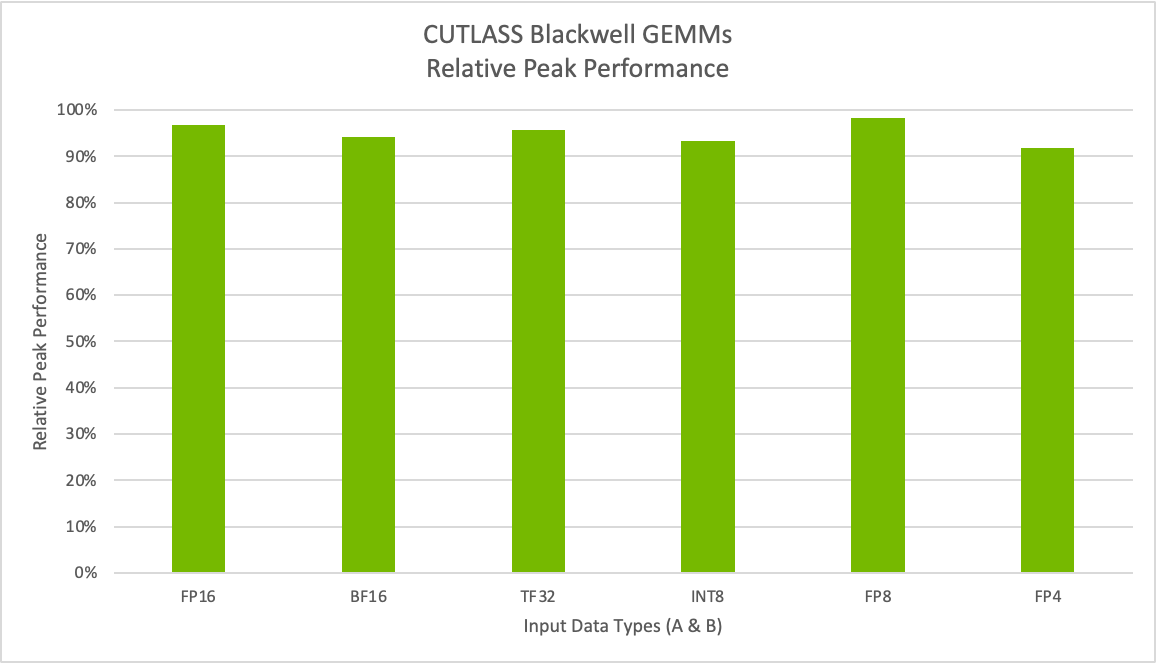
Benchmarks were performed on a B200 system. M=K=16384 and N=17290.
OpenAI Triton Support for Blackwell
OpenAI Triton compiler also now supports Blackwell, enabling developers and researchers to leverage the latest Blackwell architecture features with a Python-based compiler. OpenAI Triton can now take advantage of the latest architectural innovations in the Blackwell architecture and can achieve near-optimal performance on several critical use cases. To learn more, see OpenAI Triton on NVIDIA Blackwell Boosts AI Performance and Programmability, co-authored by NVIDIA and OpenAI.
Summary
NVIDIA Blackwell architecture incorporates many breakthrough capabilities that help accelerate generative AI inference, including second-generation Transformer Engine with FP4 Tensor Cores and fifth-generation NVLink with NVLink Switch. NVIDIA announced world-record DeepSeek-R1 inference performance at NVIDIA GTC 2025. A single NVIDIA DGX system with eight NVIDIA Blackwell GPUs can achieve over 250 tokens per second per user or a maximum throughput of over 30,000 tokens per second on the massive, state-of-the-art 671 billion parameter DeepSeek-R1 model.
A rich suite of libraries, now optimized for NVIDIA Blackwell, will enable developers to achieve significant increases in inference performance for both today’s AI models and tomorrow’s evolving landscape. Learn more about the NVIDIA AI Inference platform and stay informed about the latest AI inference performance updates.
Acknowledgements
This work would not have been possible without the exceptional contributions of many, including Matthew Nicely, Nick Comly, Gunjan Mehta, Rajeev Rao, Dave Michael, Yiheng Zhang, Brian Nguyen, Asfiya Baig, Akhil Goel, Paulius Micikevicius, June Yang, Alex Settle, Kai Xu, Zhiyu Cheng, and Chenjie Luo.
Frequently Asked Questions
Q1: What is NVIDIA Blackwell?
A: NVIDIA Blackwell is a new