{kind=link}
Enhancing the Software Stack for Blackwell
With each new platform generation, NVIDIA extensively co-designs hardware and software to allow developers to achieve high delivered workload performance. The Blackwell GPU architecture delivers large leaps in Tensor Core compute throughput and memory bandwidth. Many aspects of the NVIDIA software stack were enhanced to take advantage of the significantly improved capabilities of Blackwell in this round of MLPerf Training, including:
- Optimized GEMMs, Convolutions and Multi-head Attention: New kernels were developed to make efficient use of the faster and more efficient Tensor Cores in the Blackwell GPU architecture.
- More Efficient Compute and Communication Overlap: Architecture and software enhancements allow for better use of available GPU resources during multi-GPU execution.
- Improved Memory Bandwidth Utilization: New software was developed as part of cuDNN library that makes use of the Tensor Memory Accelerator (TMA) capability, first introduced in the Hopper architecture, improving HBM bandwidth utilization for several operations, including normalizations.
- More Performant Parallel Mapping: Blackwell GPUs introduce a larger HBM capacity, which allows for parallel mappings of language models that use hardware resources more efficiently
Additionally, to improve performance on Hopper, we enhanced cuBLAS with support for more flexible tiling options and improved data locality. Optimized Blackwell multi-head attention kernels and convolution kernels in cuDNN have leveraged cuDNN Runtime Fusion Engines. The NVIDIA Transformer Engine library has been instrumental to achieving optimized performance for language models through a combination of optimizations described above.
Blackwell Delivers a Giant Leap for LLM Pre-training
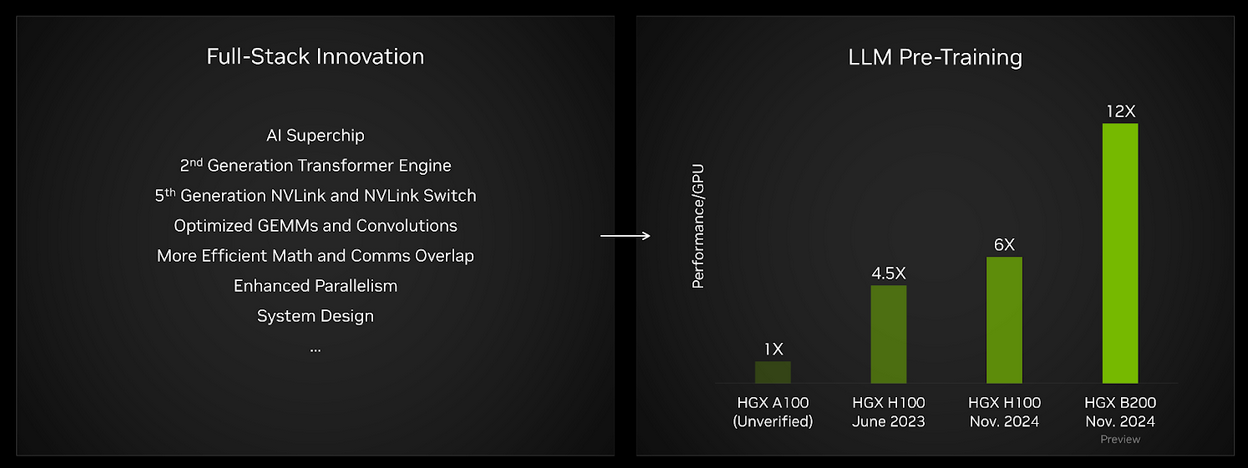
The MLPerf Training suite includes an LLM pre-training benchmark based on the GPT-3 model developed by OpenAI. This test is intended to represent state-of-the-art foundation model training performance. On a per-GPU basis, Blackwell results this round delivered twice the performance of Hopper in its fourth submission. And, compared to results gathered on HGX A100 (not verified by MLCommons) – based on the NVIDIA Ampere architecture – performance per GPU has increased by about 12x.
 Post Views: 93
Post Views: 93